Adventures in Azure Functions
I’ve been working on a small side project to help out our Talent Acquisition team at Readify. The project will help the team perform quick assessments of resumes and profiles of potential candidates, as a basic part of initially vetting the candidates for a given role - to augment a bunch of human-based assessment.
The requirements for the solution are:
- Allow a user to upload a
pdfordocxresume or profile - Extract the text from the document
- Preprocess the text by removing duplicates and punctuation
- Match the resulting unique text contents against a map of desireable skills, and undesireable skills, which fall under a basic taxonomy of categories
- Provide feedback to the user about the hits, and make a recommendation in a basic green light, yellow light, red light style
So instead of our team having to match a reasonably large array of skills against a random resume - a terrible job for a human; We are going to attempt to delegate this part of pre-qualification to the machines, who are quite good at this sort of thing.
Given that the solution requires no persistence, I thought it would be a great time to try Azure Functions. I’ve used AWS Lambda previously, and I wanted to see how functions compare.
I make sure I’ve got the Azure Functions Tools loaded into VS 2017, and File > New Project > Azure Functions
For reference the versions I’m using are:
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
<AzureFunctionsVersion>v2</AzureFunctionsVersion>
</PropertyGroup>
<ItemGroup>
...
<PackageReference Include="Microsoft.NET.Sdk.Functions" Version="1.0.13" />
</ItemGroup>One nice thing i notice immediately is that I have a solid local F5-able dev experience.
I have a class for my function, and a host.json and a local.settings.json - I’ll figure out what those are for later.
A quick bit of hacking in LinqPad and I’ve found the tools I’ll use to crack open the file formats and read the text contents: * iText7 for pdf, the successor to iTextSharp * DocumentFormat.OpenXml for docx
Both of these have no trouble taking a local file path and reading the contents of a given test docx and pdf, and both have overloads to take a Stream, which will suit my function.
So I Install-Package them into my Functions project, and whip up a reader for the PDF format first.
It looks like so:
public class PdfContentReader : IContentReader
{
public string Read(Stream content)
{
var pdfDoc = new PdfDocument(new PdfReader(content));
var pages = pdfDoc.GetNumberOfPages();
var builder = new StringBuilder();
for (var i = 1; i <= pages; i++)
{
var page = pdfDoc.GetPage(i);
var pdfText = PdfTextExtractor.GetTextFromPage(page, new SimpleTextExtractionStrategy());
builder.Append(
Encoding.UTF8.GetString(Encoding.Convert(Encoding.Default, Encoding.UTF8,
Encoding.Default.GetBytes(pdfText))));
}
pdfDoc.Close();
return builder.ToString();
}
}My function entry point looks like so:
[FunctionName("CheckFit")]
public static IActionResult Run([HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = null)]
HttpRequest req, TraceWriter log)
{
...
}Since I’m uploading a file, I expect req.Body to be a stream, which I’ll hand straight into my PDF reader.
I wire this up within my function entry point, fire up Postman, and craft a quick POST request containing a test PDF as a payload.
TRIUMPH!
This is all going a little too easily.
Now I’m going to create the DOCX reader. It looks like so:
public class DocxContentReader : IContentReader
{
public string Read(Stream content)
{
var xmlDoc = WordprocessingDocument.Open(content, false);
var bodyElement = xmlDoc.MainDocumentPart.Document.Body;
var docText = GetPlainText(bodyElement);
xmlDoc.Close();
return docText;
}
private static string GetPlainText(OpenXmlElement element)
{
var builder = new StringBuilder();
foreach (var section in element.Elements())
{
switch (section.LocalName)
{
case "t":
builder.Append(section.InnerText);
break;
case "cr":
case "br":
builder.Append(Environment.NewLine);
break;
case "tab":
builder.Append("\t");
break;
case "p":
builder.Append(GetPlainText(section));
builder.AppendLine(Environment.NewLine);
break;
default:
builder.Append(GetPlainText(section));
break;
}
}
return builder.ToString();
}
}Awesome, with that done, let’s test it again with Postman.
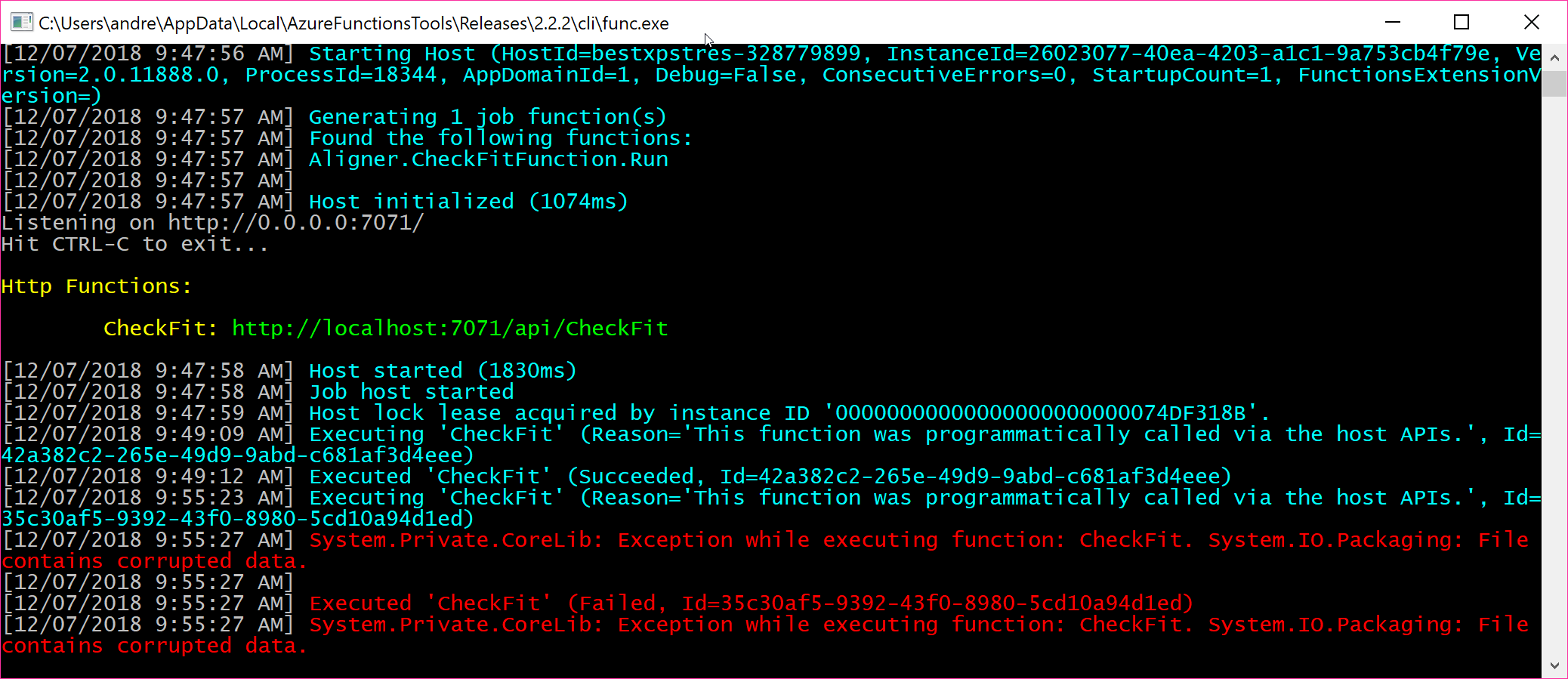
Failure
The DocumentFormat.OpenXml library isn’t at all happy with the Stream I’ve handed it.
This gives me pause for thought. I’ve handed it the same test document I used in my LinqPad test bench, so I know it can handle it when referenced by path.
Some googling around the error message and the library comes up with a bunch of people who have tried to feed it old binary-formatted .doc files, but nothing about it struggling with .docx.
So why is it breaking on my .docx stream, but not my .pdf stream?
I talk this over with Tod and Tristan as I’m hacking away on it Friday afternoon at Beer O’Clock. Conspiracy theories raised include:
- Is it a HTTP header issue -
Content*,Accept*? - Does the Azure Function host see the
docxis a Zip format and do something whacky with it while marshalling the payload? - Is there a known bug in the
DocumentFormat.OpenXmllibrary?
Tristan then chimes in with this absolute gem of an insight
Some document formats allow any amount of content before a document start identifier, like with
png.
whoa.jpg
Maybe the Stream is junk, but the PDF format / parser ignores the junk, but the DOCX format does not (given it is strict XML).
TO THE STREAM
I dump the stream to a string and inspect it, and see the following:

----------------------------240199329954201831832994\r\nContent-Disposition: form-data; name=\"document\"; filename=\"test.docx\"\r\nContent-Type: application/vnd.openxmlformats-officedocument.wordprocessingml.document\r\n\r\nPK\u0003\u0004\u0014\0\u0006\0\b\0\0\0!\0�\u0018���\u0001\0\0�\a\0\0\u0013\0\b\u0002[Content_Types].xml �\u0004\u0002(�\0\u0002\0\0\...
What are all of those HTTP headers doing in my req.Body Stream? The Stream is junk, the payload has been incorrectly parsed, and what has been handed to my Function entry point is unuseable!
I’m not happy that a bug in the framework has cost me this much sleuthing time (it was a little less compact IRL), time to pivot.
File > New Project > ASP.NET Core Web Application, Ctrl + C, Ctrl + V, change the entry point like so:
[HttpPost]
[Route("checkfit")]
{
public IActionResult Post(IFormFile file)
{
...
}A quick F5, fire up Postman and hit it with my .docx payload and…
TRIUMPH!
UPDATE:
Here is the GitHub issue I’ve lodged for the above.
DOUBLE UPDATE:
Someone has very helpfully pointed out that it likely was a header issue. Thanks WueF!